Calibre Web:个人图书管理系统
一. 前言
亚马逊中国将在2023 年6 月30 日之后停止运营 Kindle 电子书店,正式退出中国市场,自此用户将无法再通过亚马逊中国账户继续购买电子书。
Z-Library 的域名日前被美国邮政检查局查封。
现在的电子设备使用越来越频繁,它的便捷性不言而喻,阅读书籍也可以借助电子设备这种方便的工具。
在使用了各种阅读 App 后,觉得还是有一个自己的图书馆更方便,平时又喜欢搜集网络上的精品电子书,那么管理就成为了一个问题,放在硬盘的一堆电子书文件,想看也不知道看哪本,然后就想到是否可以搭建一个电子书管理平台,方便管理,搜索和下载阅读,就开始查阅网上各大神的教程,
于是就有了如下这篇搭建自己图书馆的记录。
二. 介绍
Calibre-Web 适合用来管理哪些内容:
其实除了电子书外,calibre-web 管理漫画、CG 和画集也是很方便的。
除了已经是 epub 格式的内容,其实一些其他常见漫画格式也能很方便的添加进 calibre-web 里。
比如漫画有很多只是把图片打包成 zip 文件而已,而 calibre-web 有人觉得没法直接认出 zip 格式的文件会不方便管理,其实直接把文件后缀从 zip 改成 cbz,calibre-web 就能直接认出来了,并且能直接在线阅读。这样一来很多 zip 漫画就不用费力去转 epub 格式了。(rar 和 7z 格式也是同理,但如果压缩包内有图片之外的文件或者 png 和 gif 格式的图片 calibre-web 目前认在线阅读认不出来,但可以下载下来)。
Calibre web 又有什么功能呢
calibre-web 功能很强大,主要有以下几点
- 无缝集成 calibre 单机版图书馆,只要将 calibre 的数据库文件和相应的图书复制进 calibre-web 指定目录,calibre 的所有书籍就可以通过 web 端管理阅读、推送了
- 在线阅读 pdf、epub 等格式,支持的电子书格式众多。
- 支持电子书格式在线转换,如 pdf → epub,若出现不能在线阅读,就将格式进行转换。
- 支持图书推送到自己的 kindle 设备
- 支持在线注册用户,用户权限管理(如管理员可指定用户是否拥有上传、阅读、下载等权限)
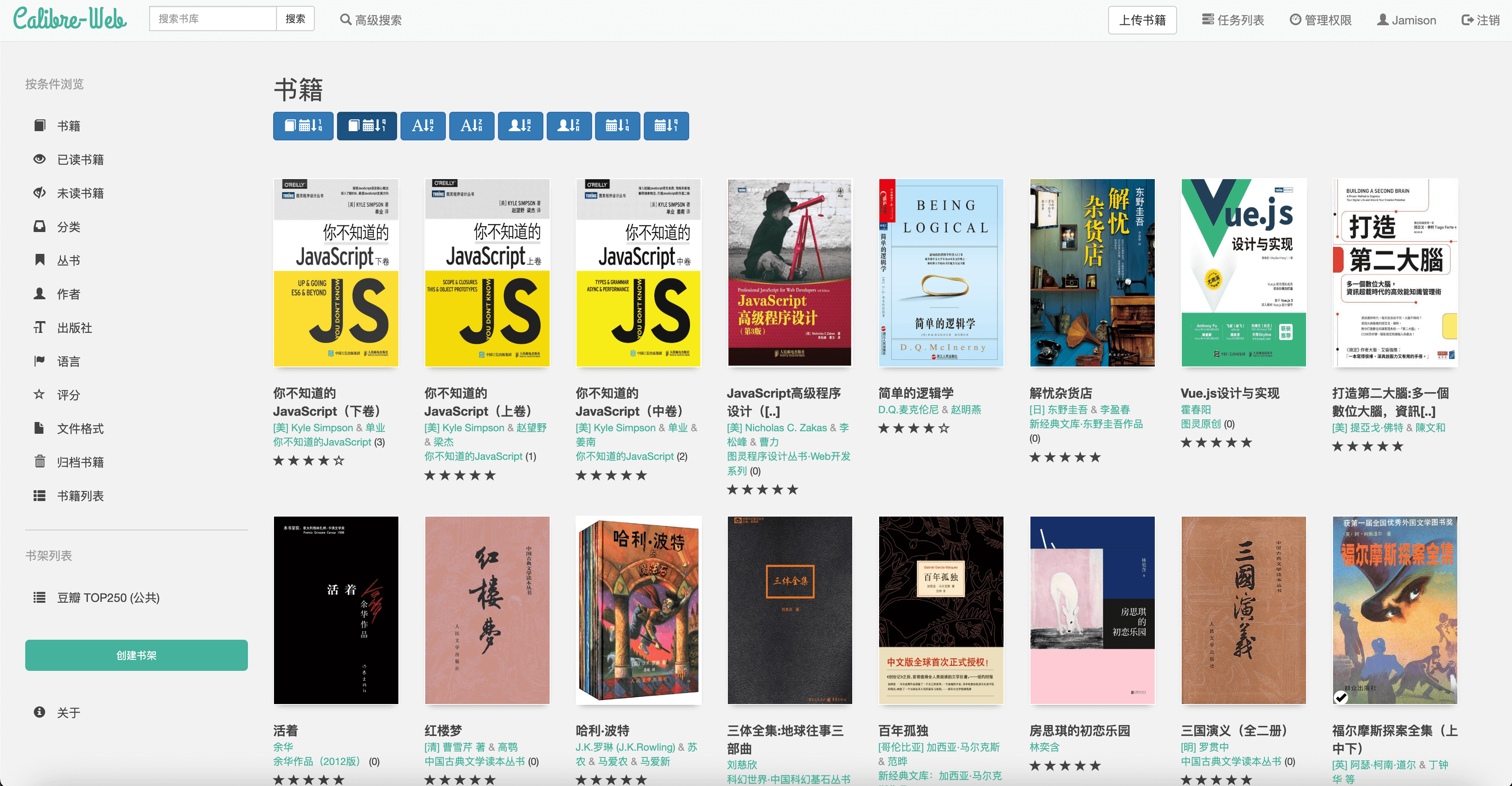
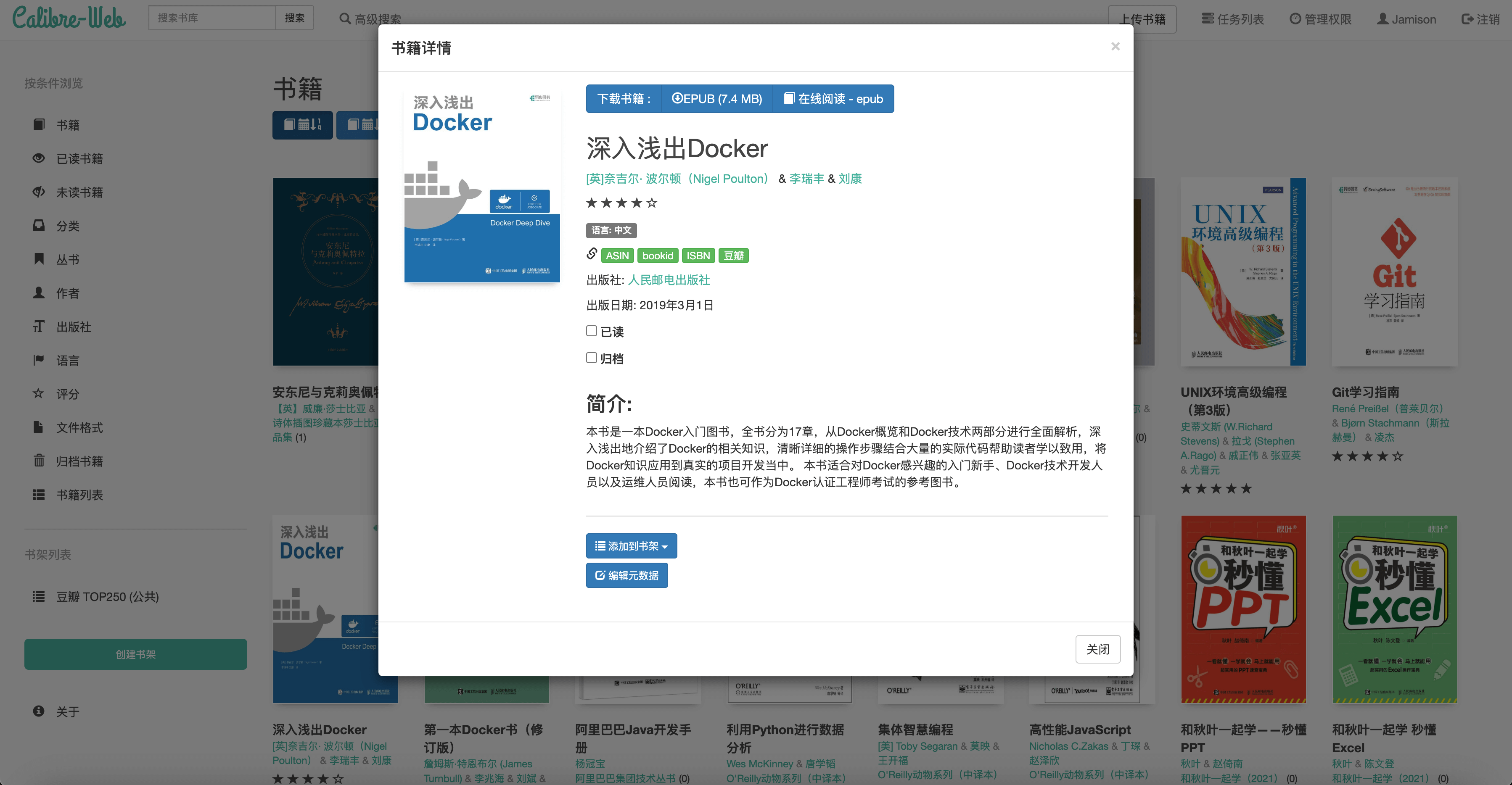
三. 效果预览
UI 看起来还是略显古老些许

四. 相关地址
Docker Hub:
五. 部署教程
1. Docker CLI:
docker run -d \
--name calibre-web \
--restart always \
--network bridge \
--cpus='1.0' \
--memory='1024m' \
-e PUID=0 \
-e PGID=0 \
-e TZ=Asia/Shanghai \
-p 8083:8083 \
-v $(pwd)/calibre-web/config:/config \
-v $(pwd)/calibre-web/NewDouban.py:/calibre-web/cps/metadata_provider \
-v $(pwd)/book:/books \
linuxserver/calibre-web:0.6.202. Docker Compose:
version: '3'
services:
calibre-web:
image: linuxserver/calibre-web:0.6.20 # 拉取固定版本镜像
container_name: calibre-web # 容器名称
restart: always # 重启策略
network_mode: bridge
deploy:
resources:
limits:
cpus: '1'
memory: 1024M
environment:
- PUID=0
- PGID=0
- TZ=Asia/Shanghai # 容器时区
# - CALIBRE_LOCALHOST=true
# - DOCKER_MODS=linuxserver/mods:universal-calibre # 可选 仅限 x86-64 添加执行电子书转换的功能
# - OAUTHLIB_RELAX_TOKEN_SCOPE=1 # 可选择设置此项以允许 Google OAUTH 工作
ports:
- '8083:8083' # 映射端口:主机 8083 -> 容器 8083
volumes:
- ./calibre-web/config:/config # 映射 cw 配置路径
- ./calibre-web/NewDouban.py:/calibre-web/cps/metadata_provider # 映射豆瓣 provider
- ./book:/books # 映射数据库路径(本地图书存放的位置)其中 -v /books 第一次需要一个初始 metadata.db 数据库文件
补充:官方文档写的 GUID \ PGID 都填 1000 ,这边不能按照官方的来,因为你不知道你系统的用户 id 是多少,如果要填写具体数据,就要在 ssh 在执行 id 用户名 来查看具体的 PGID PUID,这里使用
$(id -u) $(id -g)是一劳永逸的写法,程序运行到此就是执行命令自行获取相应的id。
数据库:metadata.db
为什么需要这个数据库文件?
由于 calibre-web 是基于 Calibre 这款软件的,它并不负责图书库的创建,所以需要有一个数据仓库, metadata.db 就是这个数据仓库。如果你不使用我的这个空库文件,也可以自己本地 创建图书库
如果您没有 Calibre 数据库,您可以使用 此数据库
默认用户:
用户名:admin
密码:password
六. 使用教程
1. 网页管理
浏览器打开 NAS_IP:8083 就可以访问项目界面了,默认登录账号是:admin / admin123
2. 配置图书馆
在 calibre-web 搭建完成后,我们要使用它的所有功能,我们要进行详细的配置。配置为了解决以下问题
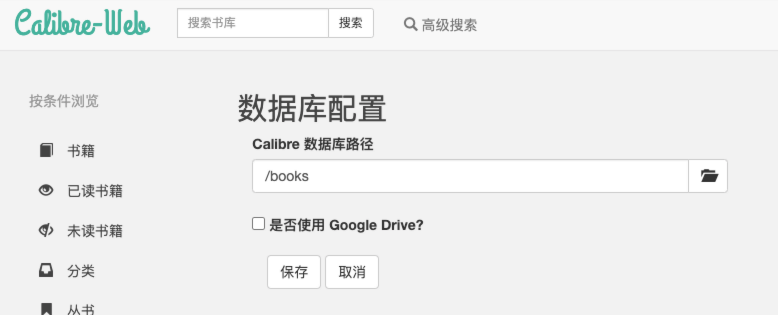
2.1 数据库
添加数据库路径为 /books (默认写法,不可更改)
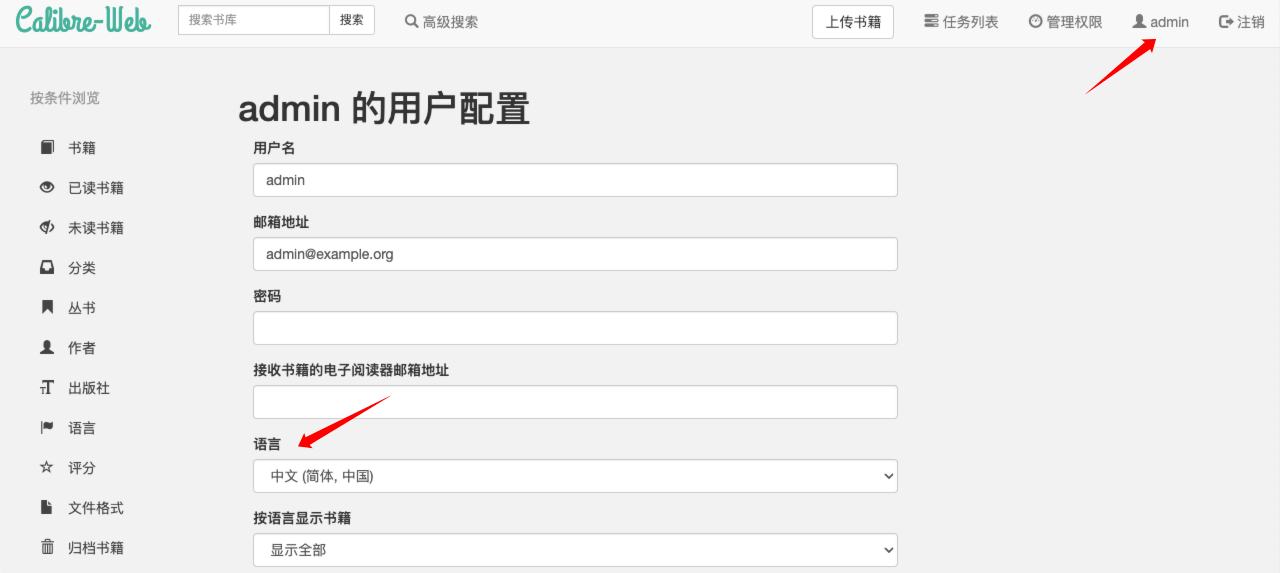
2.2 修改语言
进入右上角人头像 admin → language 中将语言切换成中文并保存。
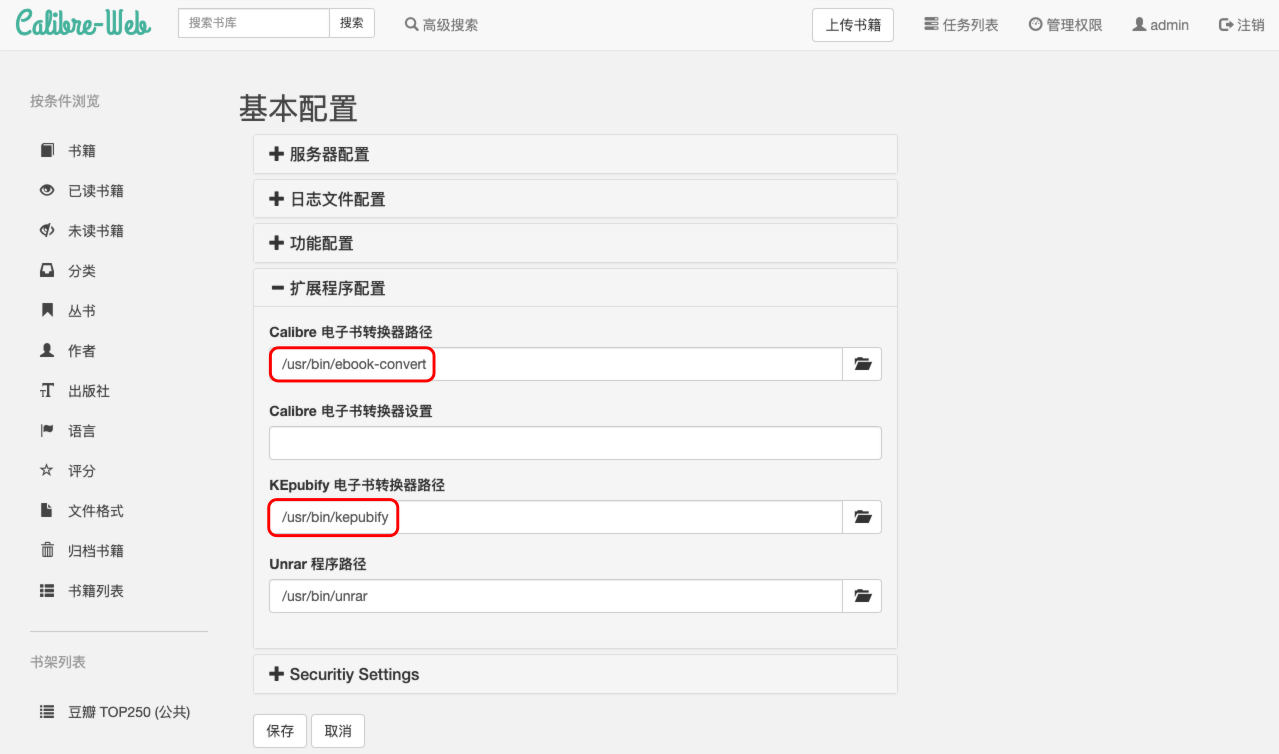
2.3 书籍转换
点击页面右上角 管理权限 → 编辑基本配置 → 扩展程序配置,进行以下修改后点击 保存
- Calibre 电子书转换器路径/usr/bin/ebook-convert
- KEpubify 电子书转换器路径/usr/bin/kepubify
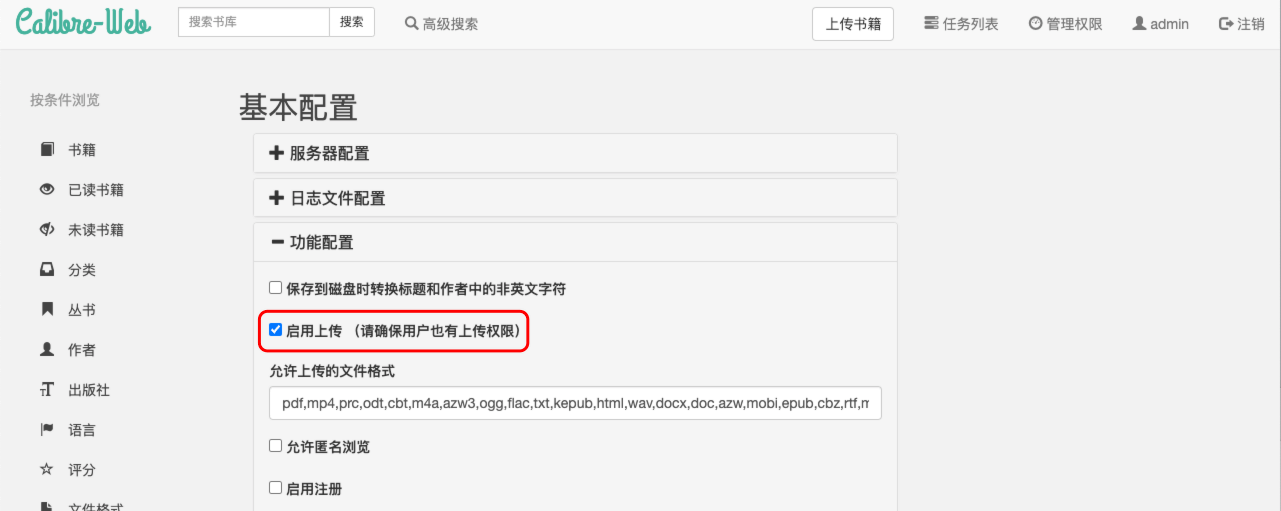
2.4 启用上传
进入 管理权限 → 编辑基本配置 → 功能配置 → 启动上传 打钩,启动注册,使用邮箱或用户名打开(Tips:注册功能需要配置发送邮箱!)
2.5 创建图书库
在电脑中安装
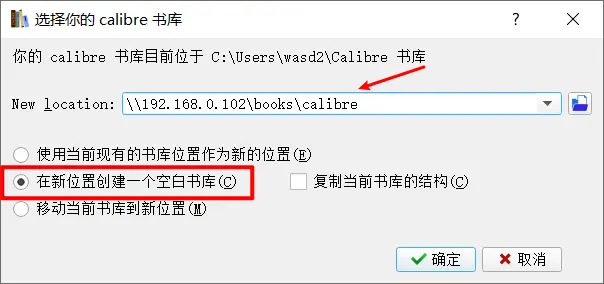
完成后,就会在该位置生成一个 metadata.db 的文件。
七. 常见问题及注意点
1. 数据库无法读取问题
请注意 docker-compose.yaml 里的 PUGDPGID 是否填写正确
2. 无法上传问题
请注意你是否打开了用户上传的权限。
3. 豆瓣元数据无法获取
豆瓣 Api 很早以前就已经不开发给个人用户使用了,目前的豆瓣 API provider 是自己开发的,使用 python 从豆瓣网站上抓取网页并解析成对应格式数据的方法实现
豆瓣 Api 镜像发布到 Docker 仓库可以启动后供 javascript 调用,但是新版 calibre-web 不再使用 javascript 调用外部服务的方式获取元数据,因此根据 calibre-web 的 metadata_provider 规范开发了 python 版本并开源到 Github 上:
Github地址:fugary/calibre-web-douban-api
使用方式是复制 src/NewDouban.py 到 calibre-web/cps/metadata_provider/ 目录下,重启项目即可,不过在群晖 Docker 环境下可以在下载后简单通过挂接的方式把文件直接挂接过去。
下载文件地址:NewDouban.py
代理下载地址:NewDouban.py
下载后存到自己的群晖中,我目前存储在 ./Calibre-Web/NewDouban.py 。
保存下方代码内容为 NewDouban.py 文件
import re
import time
import requests
from concurrent.futures import ThreadPoolExecutor, as_completed
from urllib.parse import urlparse, unquote
from lxml import etree
from functools import lru_cache
from cps.services.Metadata import Metadata, MetaSourceInfo, MetaRecord
DOUBAN_SEARCH_JSON_URL = "https://www.douban.com/j/search" # 最新豆瓣屏蔽此url
DOUBAN_SEARCH_URL = "https://www.douban.com/search"
DOUBAN_SEARCH_NEW_MODE = True
DOUBAN_BOOK_CAT = "1001"
DOUBAN_BOOK_CACHE_SIZE = 500 # 最大缓存数量
DOUBAN_CONCURRENCY_SIZE = 5 # 并发查询数
DOUBAN_BOOK_URL_PATTERN = re.compile(".*/subject/(\\d+)/?")
DEFAULT_HEADERS = {
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3573.0 Safari/537.36'
}
PROVIDER_NAME = "New Douban Books"
PROVIDER_ID = "new_douban"
class NewDouban(Metadata):
__name__ = PROVIDER_NAME
__id__ = PROVIDER_ID
def __init__(self):
self.searcher = DoubanBookSearcher()
super().__init__()
def search(self, query: str, generic_cover: str = "", locale: str = "en"):
if self.active:
return self.searcher.search_books(query)
class DoubanBookSearcher:
def __init__(self):
self.book_loader = DoubanBookLoader()
self.thread_pool = ThreadPoolExecutor(max_workers=10, thread_name_prefix='douban_async')
def calc_url(self, href):
query = urlparse(href).query
params = {item.split('=')[0]: item.split('=')[1] for item in query.split('&')}
url = unquote(params['url'])
if DOUBAN_BOOK_URL_PATTERN.match(url):
return url
def load_book_urls(self, query):
url = DOUBAN_SEARCH_JSON_URL
params = {"start": 0, "cat": DOUBAN_BOOK_CAT, "q": query}
res = requests.get(url, params, headers=DEFAULT_HEADERS)
book_urls = []
if res.status_code in [200, 201]:
book_list_content = res.json()
for item in book_list_content['items']:
if len(book_urls) < DOUBAN_CONCURRENCY_SIZE: # 获取部分数据,默认5条
html = etree.HTML(item)
a = html.xpath('//a[@class="nbg"]')
if len(a):
href = a[0].attrib['href']
parsed = self.calc_url(href)
if parsed:
book_urls.append(parsed)
return book_urls
def load_book_urls_new(self, query):
url = DOUBAN_SEARCH_URL
params = {"cat": DOUBAN_BOOK_CAT, "q": query}
res = requests.get(url, params, headers=DEFAULT_HEADERS)
book_urls = []
if res.status_code in [200, 201]:
html = etree.HTML(res.content)
alist = html.xpath('//a[@class="nbg"]')
for link in alist:
href = link.attrib['href']
parsed = self.calc_url(href)
if parsed:
if len(book_urls) < DOUBAN_CONCURRENCY_SIZE:
book_urls.append(parsed)
return book_urls
def search_books(self, query):
if DOUBAN_SEARCH_NEW_MODE:
book_urls = self.load_book_urls_new(query)
else:
book_urls = self.load_book_urls(query)
books = []
futures = [self.thread_pool.submit(self.book_loader.load_book, book_url) for book_url in book_urls]
for future in as_completed(futures):
book = future.result()
if book is not None:
books.append(future.result())
return books
class DoubanBookLoader:
def __init__(self):
self.book_parser = DoubanBookHtmlParser()
@lru_cache(maxsize=DOUBAN_BOOK_CACHE_SIZE)
def load_book(self, url):
book = None
start_time = time.time()
res = requests.get(url, headers=DEFAULT_HEADERS)
if res.status_code in [200, 201]:
print("下载书籍:{}成功,耗时{:.0f}ms".format(url, (time.time() - start_time) * 1000))
book_detail_content = res.content
book = self.book_parser.parse_book(url, book_detail_content.decode("utf8"))
return book
class DoubanBookHtmlParser:
def __init__(self):
self.id_pattern = DOUBAN_BOOK_URL_PATTERN
self.date_pattern = re.compile("(\\d{4})-(\\d+)")
self.tag_pattern = re.compile("criteria = '(.+)'")
def parse_book(self, url, book_content):
book = MetaRecord(
id="",
title="",
authors=[],
publisher="",
description="",
url="",
source=MetaSourceInfo(
id=PROVIDER_ID,
description=PROVIDER_NAME,
link="https://book.douban.com/"
)
)
html = etree.HTML(book_content)
title_element = html.xpath("//span[@property='v:itemreviewed']")
book.title = self.get_text(title_element)
share_element = html.xpath("//a[@data-url]")
if len(share_element):
url = share_element[0].attrib['data-url']
book.url = url
id_match = self.id_pattern.match(url)
if id_match:
book.id = id_match.group(1)
img_element = html.xpath("//a[@class='nbg']")
if len(img_element):
cover = img_element[0].attrib['href']
if not cover or cover.endswith('update_image'):
book.cover = ''
else:
book.cover = cover
rating_element = html.xpath("//strong[@property='v:average']")
book.rating = self.get_rating(rating_element)
elements = html.xpath("//span[@class='pl']")
for element in elements:
text = self.get_text(element)
if text.startswith("作者") or text.startswith("译者"):
book.authors.extend([self.get_text(author_element) for author_element in
filter(self.author_filter, element.findall("..//a"))])
elif text.startswith("出版社"):
book.publisher = self.get_tail(element)
elif text.startswith("副标题"):
book.title = book.title + ':' + self.get_tail(element)
elif text.startswith("出版年"):
book.publishedDate = self.get_publish_date(self.get_tail(element))
elif text.startswith("丛书"):
book.series = self.get_text(element.getnext())
summary_element = html.xpath("//div[@id='link-report']//div[@class='intro']")
if len(summary_element):
book.description = etree.tostring(summary_element[-1], encoding="utf8").decode("utf8").strip()
tag_elements = html.xpath("//a[contains(@class, 'tag')]")
if len(tag_elements):
book.tags = [self.get_text(tag_element) for tag_element in tag_elements]
else:
book.tags = self.get_tags(book_content)
return book
def get_tags(self, book_content):
tag_match = self.tag_pattern.findall(book_content)
if len(tag_match):
return [tag.replace('7:', '') for tag in
filter(lambda tag: tag and tag.startswith('7:'), tag_match[0].split('|'))]
return []
def get_publish_date(self, date_str):
if date_str:
date_match = self.date_pattern.fullmatch(date_str)
if date_match:
date_str = "{}-{}-1".format(date_match.group(1), date_match.group(2))
return date_str
def get_rating(self, rating_element):
return float(self.get_text(rating_element, '0')) / 2
def author_filter(self, a_element):
a_href = a_element.attrib['href']
return '/author' in a_href or '/search' in a_href
def get_text(self, element, default_str=''):
text = default_str
if len(element) and element[0].text:
text = element[0].text.strip()
elif isinstance(element, etree._Element) and element.text:
text = element.text.strip()
return text if text else default_str
def get_tail(self, element, default_str=''):
text = default_str
if isinstance(element, etree._Element) and element.tail:
text = element.tail.strip()
if not text:
text = self.get_text(element.getnext(), default_str)
return text if text else default_str总之,搭建过程还是较为麻烦,涉及的方面较多,需要了解相关的基础知识,但是此篇教程我写的较为详细,相信只要耐心都能搭建成功,毕竟我使用这个有一段时间了,有的需要注意的地方我都写出来了,Docker 映像也选择好了, 注意文件夹的权限是一个大坑,搭建不成功很大方面是这个原因。
